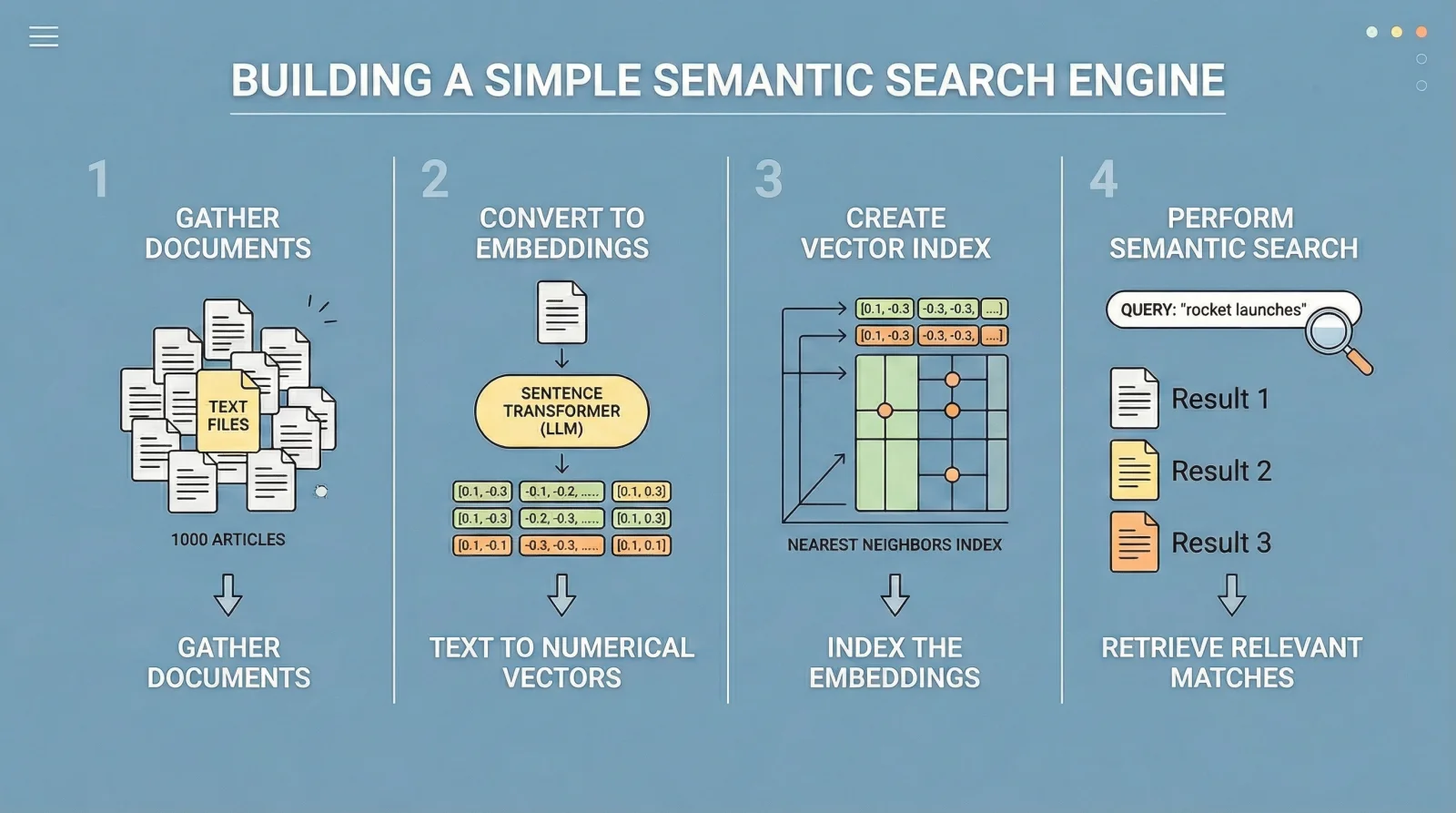
Can LLM Embeddings Improve Time Series Forecasting? A Practical Feature Engineering Approach
Using large language models (LLMs) — or their outputs, for that matter — for all kinds of machine learning-driven tasks, including...
4 min read
772 views
Read More →