In this article, you will learn how to move an AI agent from a promising prototype to a reliable, scalable production system by selecting the right architecture, building the proper infrastructure, and executing a pragmatic rollout plan.
Topics we will cover include:
Core execution models for agents and how to choose among stateless, stateful, and event-driven patterns
The five-layer infrastructure stack — compute, storage, communication, observability, and security — and why each layer matters
Deployment topologies, human oversight patterns, and a step-by-step implementation roadmap with CI/CD and monitoring
Let’s explore these together.
Deploying AI Agents to Production: Architecture, Infrastructure, and Implementation Roadmap Image by Author
You’ve built an AI agent that works well in development. It handles complex queries, calls the right tools, and produces solid results. Now comes the hard part: getting it to work reliably in production at scale.
The architecture and infrastructure decisions you make here determine whether your agent becomes a useful production system or an expensive experiment that never quite works. Let’s look at the patterns and practices that make agent deployments succeed.
1. Architecture Patterns: Choosing How Your Agent Runs
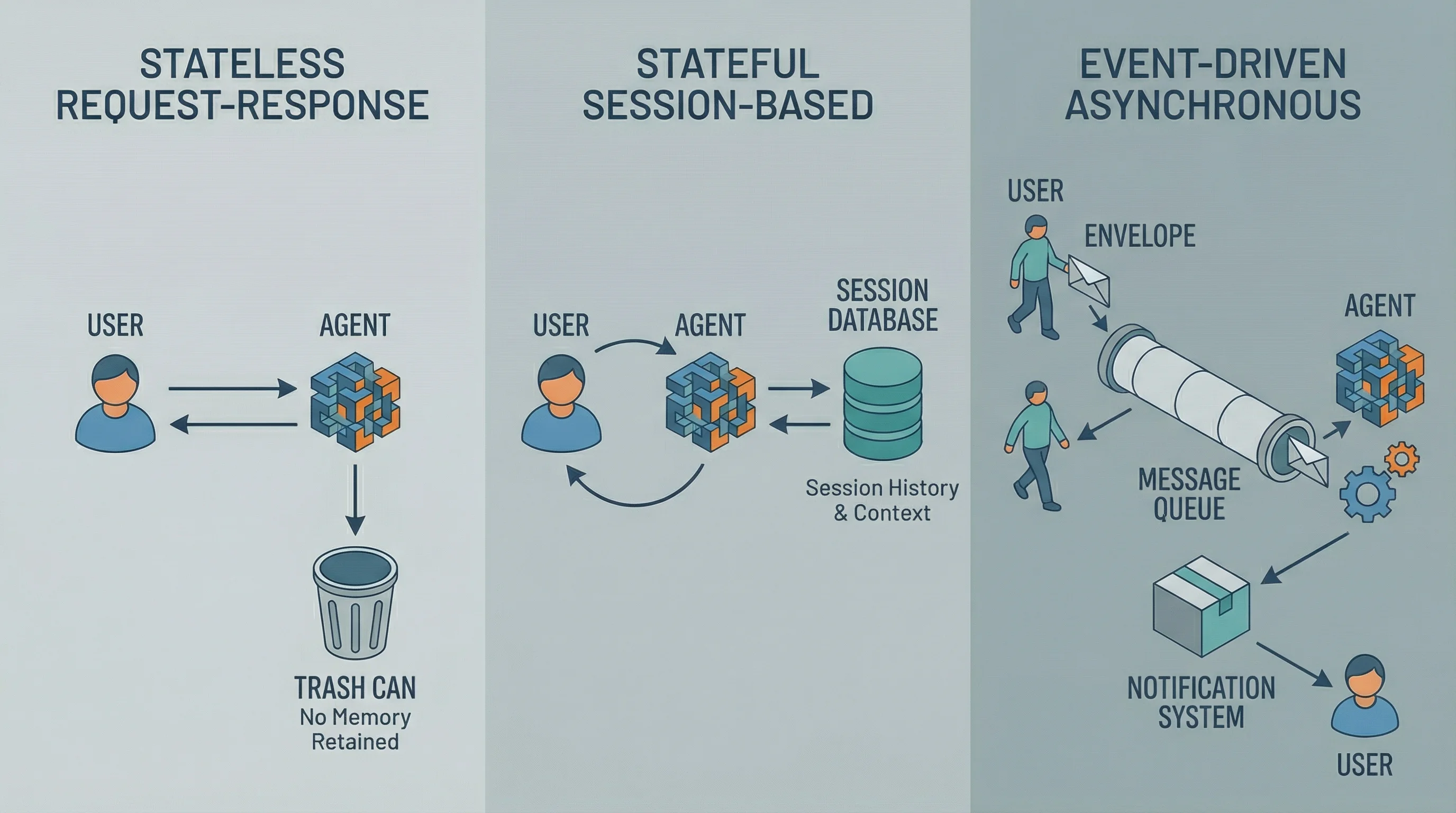
Your first big decision is picking the right execution model for your agent. Three core patterns show up in most production deployments.
A visual comparison of the three primary architecture patterns, highlighting differences in request flow and state management.
Stateless Request-Response Agents work like traditional APIs. Each request comes in fresh with no memory of what happened before. This pattern works well for document analysis, data extraction, or classification tasks. The advantage is simplicity: scale horizontally by adding more instances, and if one fails, it doesn’t affect the others. The catch is that agents retain no memory between turns, so every bit of context needs to come in with each request payload.
Stateful Session-Based Agents remember what you’ve discussed. Customer service chatbots or coding assistants recall your earlier questions and build on previous context. These agents store session state (conversation history, user preferences, intermediate results) either in memory or a database. The challenge is managing this state: where does it live, how long does it persist, and what happens when an agent crashes mid-conversation? You can store session state in Redis for short-term conversations or databases for longer persistence. Load balancers need session affinity to route users back to the same agent instance, or you’ll need shared state that any instance can access.
Event-Driven Asynchronous Agents respond to events rather than direct requests. A user submits a complex task, gets immediate acknowledgment, and receives notification when it’s complete. These agents pull work from message queues, process tasks that might involve multiple tool calls and extended reasoning, then publish results when done. This pattern handles long-running workflows without blocking your interface. The tradeoff is complexity: you’re now managing message queues, worker pools, result storage, and notification systems.
Most production systems mix these patterns. A customer service platform might use stateless agents for FAQ lookups, stateful agents for ongoing support conversations, and event-driven agents for complex case investigations that require pulling data from multiple systems.
2. Infrastructure Stack: What Agents Need to Run
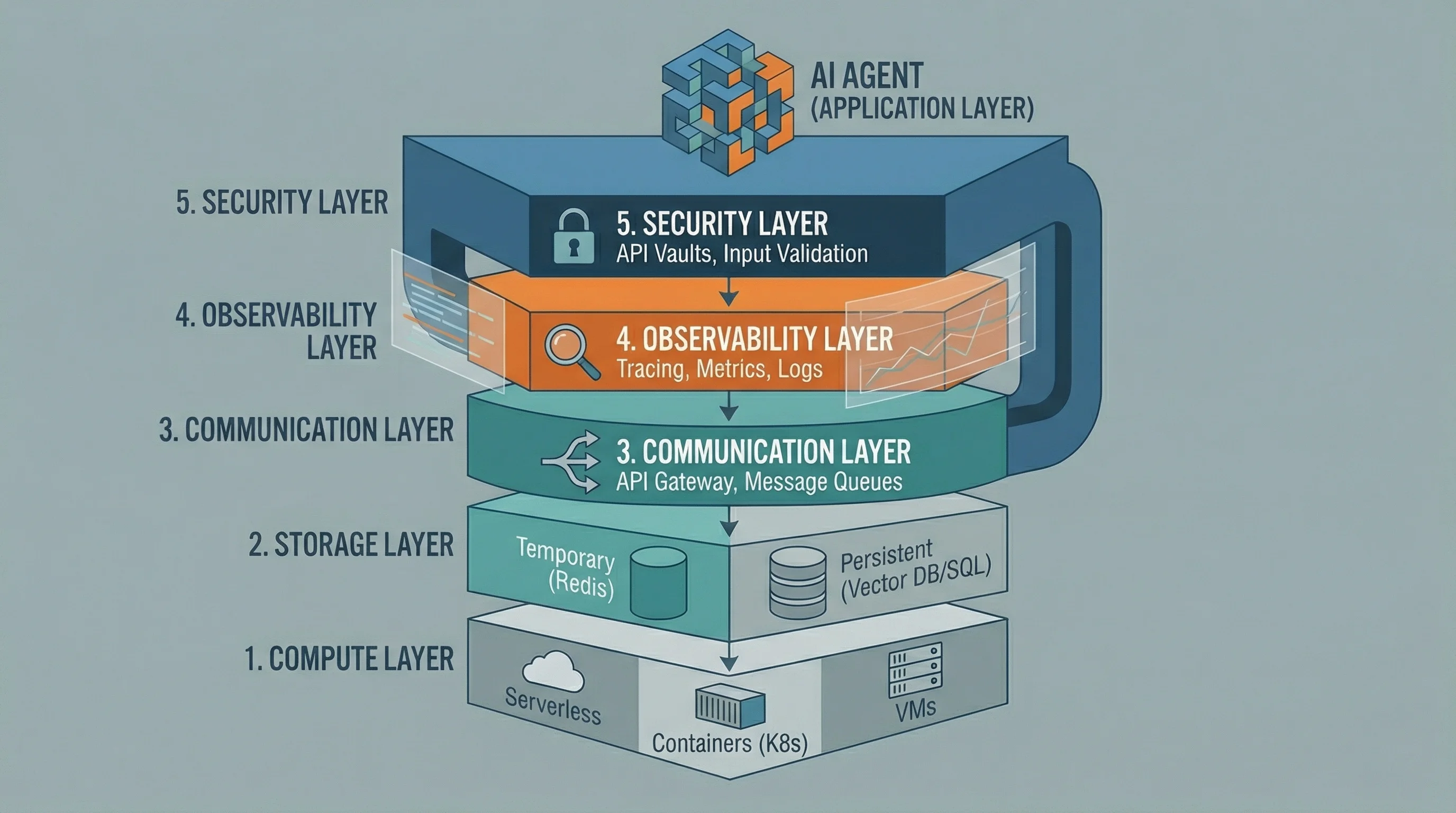
Production agents need five infrastructure layers.
The five-layer infrastructure stack required to reliably support AI agents in a production environment.
Compute Layer is where your agent code actually runs. Serverless functions (AWS Lambda, Google Cloud Run) work well for stateless agents with unpredictable traffic. Containerized deployments (ECS, Kubernetes) fit stateful agents needing consistent environments. Dedicated VMs handle high-volume scenarios where cold starts are unacceptable. Serverless minimizes idle costs but introduces latency. Containers provide consistency but require orchestration. VMs offer maximum control at maximum complexity.
Storage Layer handles both temporary and persistent state. Temporary storage holds conversation history during active sessions (Redis excels here with its speed and automatic expiration). Persistent storage maintains long-term memory, tool call history, and evaluation data. Vector databases like Pinecone or Weaviate store embeddings for semantic memory. Traditional databases store structured data. Here’s where things get tricky: memory systems increase infrastructure complexity, so think about what actually needs to persist.
Communication Layer connects agents to the outside world. REST APIs work for synchronous request-response patterns. WebSockets enable real-time streaming responses for conversational agents. Message queues (RabbitMQ, AWS SQS) coordinate asynchronous workflows and multi-agent systems. API gateways sit in front of your agents, handling authentication, rate limiting, and request routing. This layer also includes integrations to external tools and services your agent calls, each requiring credential management, error handling, and retry logic.
Observability Layer gives you visibility into agent behavior. Structured logging captures the agent’s reasoning process, tool calls, and decisions. Metrics track success rates, latency, and token usage. Distributed tracing follows requests through multi-agent workflows. LangSmith, LangFuse, or custom solutions capture agent-specific data that traditional APM tools miss. Without observability, debugging LLM behavior becomes nearly impossible.
Security Layer controls access and protects data. API keys live in vaults (AWS Secrets Manager, HashiCorp Vault), not environment variables. Network policies restrict agent access. Input validation prevents prompt injection. Output filtering catches sensitive information. This layer handles compliance requirements around data retention and audit trails. For implementing specific checks like input firewalls for prompt injection and PII redaction, see The 3 Invisible Risks Every LLM App Faces (And How to Guard Against Them).
3. Deployment Topologies: Structuring Agent Systems at Scale
How you organize agents in production depends on task complexity and volume requirements.
Single Agent Deployments handle one specific capability. A document analysis agent processes PDFs and returns structured data. A SQL generation agent converts natural language to database queries. These focused agents are easiest to develop, test, and maintain. Deploy multiple instances behind a load balancer for scaling. The limitation is scope: they can’t handle workflows requiring multiple capabilities.
Multi-Agent Distributed Systems divide complex tasks across specialized agents. A customer service system might include a routing agent that classifies inquiries, specialist agents for billing, technical support, and account management, plus an orchestrator that coordinates responses. Each agent runs independently, communicating through message queues or API calls. This gives you flexibility (you can scale each specialist independently based on demand) but requires careful orchestration to prevent cascading failures and manage token costs when agents talk to each other.
Agent Pools with Load Balancing handle high-volume scenarios where many identical agents process similar requests. Ten instances of your customer support agent sit behind a load balancer, each processing requests independently. Auto-scaling policies add or remove instances based on queue depth or response latency. The challenge is managing stateful interactions: either use sticky sessions to route users to the same instance, or externalize session state so any instance can handle any request.
Hierarchical Agent Systems use supervisor-worker patterns for complex workflows. A supervisor agent breaks down tasks, delegates to specialized workers, monitors progress, and synthesizes results. Workers report completion status and intermediate results. This pattern works well for research tasks, data analysis pipelines, or content generation workflows where quality review is essential. The supervisor can implement retry logic, quality checks, and error recovery without complicating worker logic.
Your topology choice directly impacts infrastructure needs. Single agents need simple compute and load balancing. Multi-agent systems require message queues, service discovery, and complex monitoring. Hierarchical systems need workflow orchestration and state management.
Human Oversight Patterns: Regardless of topology, high-stakes decisions often require human approval before execution. Semi-autonomous workflows pause at critical decision points (financial transactions, medical recommendations, legal document finalization) and await explicit human approval via webhook or API before proceeding. This pattern requires stateful orchestration that can maintain a “pending” status for hours or days while preserving full execution context. Common in healthcare, financial services, and legal applications where autonomous decisions carry significant risk or regulatory implications.
4. Implementation Roadmap: From Development to Production
Moving from local development to production requires four stages.
Containerization comes first. Package your agent code, dependencies, and configuration into Docker containers. Use multi-stage builds to keep images small: base images with system dependencies, then your application layer with Python packages and model artifacts. Environment variables provide API keys and configuration without hardcoding secrets. Health check endpoints verify both the container and external dependencies (LLM APIs, databases) are responsive. Container registries (Docker Hub, AWS ECR) store versioned images. This gives you consistent execution across development, testing, and production environments.
Cloud Deployment moves containers to managed infrastructure. For stateless agents with variable traffic, serverless platforms like AWS Lambda or Google Cloud Run provide automatic scaling and pay-per-use pricing. Configure memory limits based on your agent’s needs (LLM applications need 1-2GB minimum). Set timeout values accounting for extended reasoning: a 30-second timeout might work for simple queries but fails for complex multi-step reasoning. For stateful agents, container orchestration platforms (ECS, Kubernetes) provide persistent compute with load balancing and automatic restarts. Configure readiness and liveness probes so the orchestrator knows when instances are healthy.
CI/CD Pipelines automate testing and deployment. When you commit code changes, automated workflows run your evaluation suite using LLM metrics (the same metrics validating quality in development now gate production deployments). If evaluations pass, the pipeline builds new container images, pushes them to the registry, and triggers deployment. Blue-green deployment patterns let you run old and new versions simultaneously, routing a small percentage of traffic to the new version while monitoring for issues. For high-risk agent updates, use shadow deployment: route live traffic to both current and new agent versions, but only return the current agent’s response to the user. The new agent processes the request silently in the background, logging its reasoning and results for offline comparison. This lets you validate probabilistic variance on real-world data without risking user experience. If problems emerge, automated rollback returns to the previous version. Version control extends beyond code to prompts, tool definitions, and configuration (everything that changes agent behavior needs versioning and testing).
Monitoring and Observability transform black-box agents into observable systems. Structured logging captures each reasoning step, tool call, and decision in JSON format, making it queryable for debugging. Custom metrics track agent-specific concerns: tool call success rates by tool name, reasoning chain length, user satisfaction scores, and most important, Cost Per Task. While engineers track tokens, business stakeholders need to know the cost per resolved ticket or cost per analysis to prove ROI. Set up cost alerts when daily token consumption exceeds thresholds (token costs in production can spiral quickly without monitoring). Distributed tracing follows requests through multi-agent systems, showing which agent consumed which tokens and where latency accumulated. Integrate with LangSmith or similar platforms for agent-specific visualization of reasoning chains and tool interactions.
5. Decision Framework: Matching Architecture to Requirements
Choosing the right deployment approach means mapping your needs to architectural patterns.
Start with your scaling requirements. If you expect fewer than 100 requests per hour with sporadic traffic, serverless stateless agents minimize costs. If you need to handle thousands of concurrent conversations with sub-second response times, containerized stateful agents with dedicated compute provide consistent performance. If some tasks complete in seconds while others take hours, event-driven patterns prevent blocking and enable better resource use.
Consider your state requirements. Stateless patterns work when each request is independent (document analysis, classification, data extraction). If users expect “remember what I told you earlier,” you need stateful sessions with appropriate storage. If tasks involve multi-step workflows spanning minutes or hours, event-driven patterns with persistent state tracking are essential.
Evaluate your complexity tolerance. Single stateless agents are simplest to deploy and debug. Multi-agent systems provide flexibility and specialization but multiply operational complexity. Start simple, measure, and add complexity only when simpler approaches fail to meet requirements.
Account for your budget constraints. Token economics apply directly to architecture. Serverless functions that wake up for each request might make unnecessary LLM calls during initialization. Long-running containers can cache embeddings and reduce repeated computation. Event-driven systems that batch similar requests can reduce token usage. Your architecture directly impacts operational costs.
Factor in your team’s expertise. If you have experienced DevOps engineers, Kubernetes provides maximum flexibility. If you’re a small team, managed services like Cloud Run or AWS Fargate abstract infrastructure complexity. The best architecture is one your team can actually operate.
Wrapping Up
Deployment architecture isn’t about using the newest technology or the most complex patterns. It’s about matching your agent’s requirements to infrastructure that can reliably, cost-effectively, and maintainably support those requirements in production. The patterns and infrastructure described here provide the foundation, but your specific use case, scale, and constraints will guide your choices.
Start with the simplest architecture that could work, instrument it thoroughly, and let production data guide evolution. The agent that ships beats the perfect architecture that never deploys.